El trabajo de un Data Scientist en el mundo del Business Intelligence se podría resumir en 3 grandes grupos de tareas:
- Generación de Insights: analizar los datos para encontrar resultados y conclusiones que puedan tener impacto en el negocio de la empresa.
- Creación de Informes, cuadros de mando y Dashboards: permiten organizar la información relevante para la empresa, estructurándola, analizándola y presentándola en forma de resultados visualmente atractivos y fácilmente entendibles por los usuarios de negocio.
- Proyectos Ad hoc: problemas concretos que preocupan en un momento dado y que pueden ser resueltos mediante análisis de datos.
Este proyecto contiene casos de los 3 tipos de tareas típicas de un Data Scientist con diferentes herramientas: SQL, PowerBI, Python.
Contexto
Trabajamos para una Ecommerce que vende productos frescos y saludables. Es una startup llamada ‘SanoyFresco’ que estaba creciendo mucho, pero por algún motivo en el último año ha empezado a perder muchas ventas. Y por eso han decidido invertir en contratar a analistas de datos para empezar a tomar las decisiones de una manera más profesional basándose en datos.
Lo primero que vas a hacer es analizar datos para entender cómo está la situación de las ventas. Es algo que el director general suele pedir para presentarlo en el Consejo de Administración.
Después vas a crear un cuadro de mando para solucionar el primer problema urgente de la empresa que es la falta de una fuente de información única. Cada director de cada departamento lleva a las reuniones sus propios datos y al final es imposible ponerse de acuerdo y tomar decisiones basándose en datos. Pondremos orden en toda esta información y crearemos la fuente única de la verdad en cuanto a datos que será utilizada en la empresa a partir de ahora.
Tras ello nos piden que ayudemos en la parte de intentar remontar las ventas. Y para ello vamos a crear un algoritmo en Python que analice el histórico de las compras y localice patrones consistentes en los datos que nos permiten incrementar las futuras ventas. Del estilo de: ‘si el cliente ha comprado esto, entonces también tiene muy alta probabilidad de estar interesado en esto otro’, y por lo tanto se lo vamos a recomendar en el recomendador de la página del Ecommerce. Esto va a ayudar a aumentar el ‘Ticket Medio de Compra’.
Y, por último, le daremos al usuario de negocio una interfaz gráfica y amigable con la que interactuar con el algoritmo que has construido. El usuario de negocio no conoce Python y no va a saber trabajar a partir del código que tú escribas, así que crearemos una especie de aplicación en PowerBI para que él pueda acceder a esas reglas, a esos patrones, identificados por el algoritmo de una manera totalmente visual y no técnica.
1. Generación de Insights con SQL
Objetivos
Generar Insights del negocio para presentar en el Consejo de Administración
Instrucciones
Lo haremos directamente contra la base de datos, sin extraer información dado que solo necesitamos unos datos puntuales. Usaremos SQL y son consultas muy sencillas.
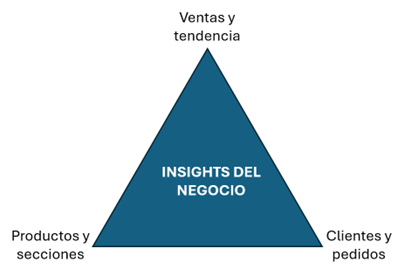
Utilizaremos el framework de la pirámide que nos sirva como guía para decidir qué preguntas, es decir qué consultas, queremos extraer de la base de datos. Son mapas de ruta muy útiles que nos permiten separar el grano de la paja ante tanto dato para dar respuesta a lo que nos interesa saber.
Diseño Analítico
Para realizar un análisis integral del negocio es importante seguir un enfoque estructurado que vaya de lo general a lo específico. Comenzaremos con una visión general de las ventas totales, luego analizaremos la tendencia de las mismas, profundizaremos en los productos y finalmente examinaremos el comportamiento de los clientes y de los pedidos.
Daremos respuesta acerca de la situación de las ‘Ventas y tendencia’, los ‘Productos y secciones’ y los ‘Clientes y pedidos’ mediante las siguientes preguntas:
Pregunta 0: ¿Qué datos contiene la tabla a analizar?
VENTAS Y TENDENCIA
Pregunta 1: ¿Cuál es el ingreso total generado por el negocio?
Pregunta 2: ¿Cómo ha sido la tendencia de ingresos mensuales?
PRODUCTOS Y SECCIONES
Pregunta 3: ¿Cuál es el rendimiento de cada departamento en términos de ventas?
Pregunta 4: ¿Cómo se distribuyen las ventas entre las diferentes secciones?
Pregunta 5: ¿Cuáles son los 10 productos más vendidos en cantidad?
Pregunta 6: ¿Qué 10 productos generan más ingresos?
CLIENTES Y PEDIDOS
Pregunta 7: ¿Quiénes son los 20 clientes que más compran en términos de ingresos?
Pregunta 8: ¿Cuál es la compra media por cliente?
Pregunta 9: ¿Cuántos pedidos totales se han realizado?
Pregunta 10: ¿Cuál es el valor promedio por pedido?
Desarrollo
Y con estas consultas SQL damos respuesta a esas preguntas:
-- 0 PREGUNTA
SELECT * FROM tickets LIMIT 100;
--1 PREGUNTA
SELECT SUM(precio_total) AS ingreso_total FROM tickets;
-- 2 PREGUNTA
SELECT strftime('%Y-%m', fecha) AS mes, SUM (precio_total) AS ingreso_meansual
from tickets
GROUP BY mes
ORDER BY mes;
-- 3 PREGUNTA
SELECT id_departamento, SUM(precio_total) AS ventas_departamento FROM tickets
GROUP BY id_departamento
ORDER BY ventas_departamento DESC;
-- 4 PREGUNTA
SELECT id_seccion, SUM(precio_total) AS ventas_seccion FROM tickets
GROUP BY id_seccion
ORDER BY ventas_seccion DESC;
-- 5 PREGUNTA
SELECT nombre_producto, SUM(cantidad) AS top10_cantidad FROM tickets
GROUP BY nombre_producto
ORDER BY top10_cantidad DESC
LIMIT 10;
-- 6 PREGUNTA
SELECT nombre_producto, SUM(precio_total) AS top10_ingresos FROM tickets
GROUP BY nombre_producto
ORDER BY top10_ingresos DESC
LIMIT 10;
-- 7 PREGUNTA
SELECT id_cliente, SUM(precio_total) AS top20_clientes FROM tickets
GROUP BY id_cliente
ORDER BY top20_clientes DESC
LIMIT 20;
-- 8 PREGUNTA
SELECT AVG (compra_total_cliente) AS compra_media_cliente
FROM(SELECT id_cliente, SUM(precio_total) AS compra_total_cliente
FROM tickets
GROUP BY id_cliente) subconsulta;
-- 9 PREGUNTA
SELECT COUNT(DISTINCT (id_pedido)) AS total_pedidos from tickets;
-- 10 PREGUNTA
SELECT AVG (precio_total_pedido) AS media_pedido
FROM(SELECT id_pedido, SUM(precio_total) AS precio_total_pedido
from tickets
GROUP BY id_pedido)subconsulta;
Conclusiones
- La disminución de las ventas se debe a la pérdida de clientes. Pero los clientes que se quedan compran más.
- Aumento del ticket medio por cliente y por pedido.
💡 TIP
El trabajo del analista de datos sigue la estrategia: Análisis de datos → Evidencias → Insights
Sin embargo, al comunicar los resultados a personal no especializado, el framework de la pirámide recomienda presentarlo en orden inverso: Insights → Evidencias → Análisis de datos
2. Creando un Algoritmo con Python
Objetivos
A largo plazo: trabajar en la adquisición y fidelización de clientes.
A corto plazo: incrementar las ventas.
Instrucciones
Crear un algoritmo de Python que permita vender más productos en cada transacción. El algoritmo estará basado en la técnica ‘Market Basket Analysis’.
Diseño Analítico
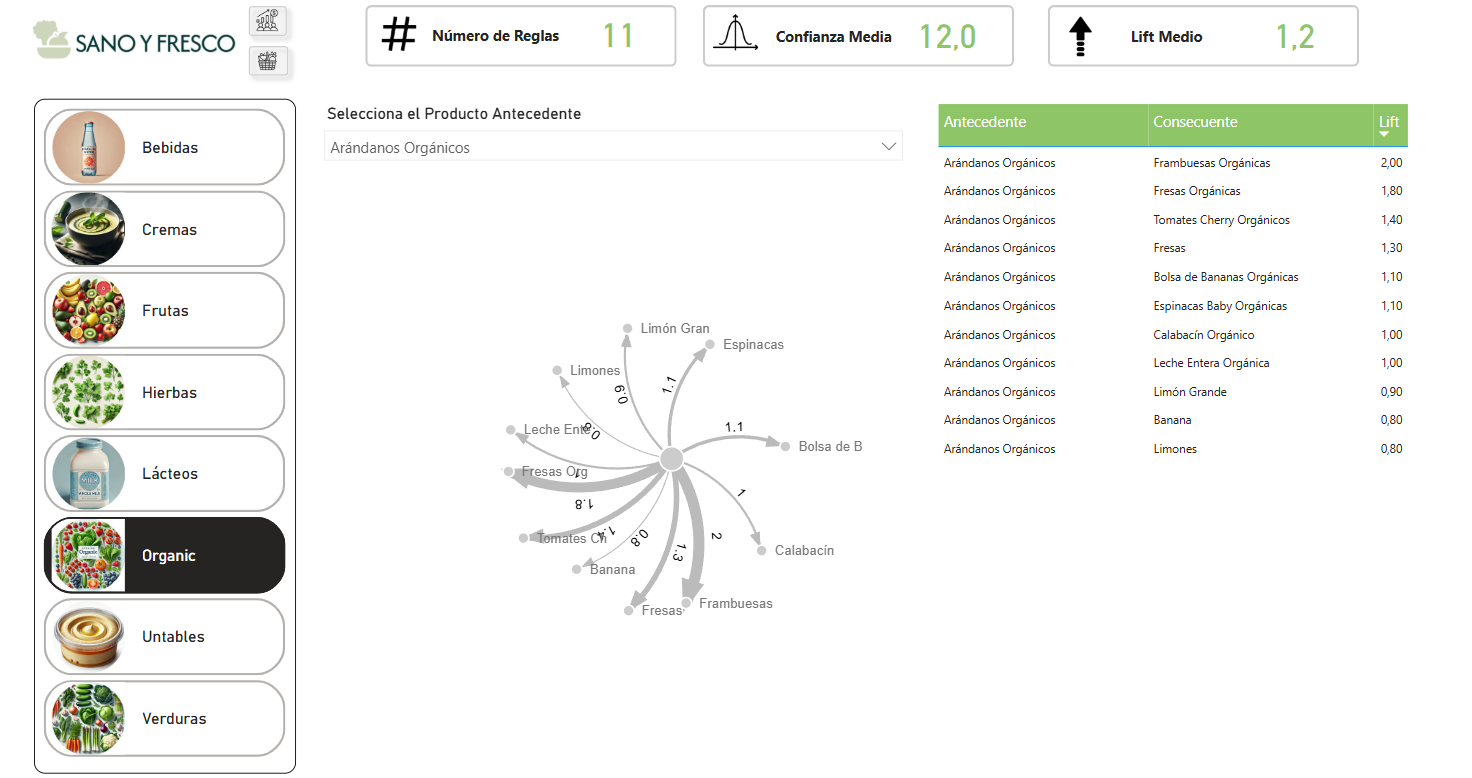
‘Market Basket Analysis’: metodología muy usada en todo tipo de empresas para hacer recomendaciones personalizadas a cada usuario en base a lo que ya ha comprado o en lo que tiene interés.
Conceptos clave:
- Antecedente (A): el “si…”. Conjunto de ítems en el lado izquierdo de la regla. Ej.: A = {manzana}.
- Consecuente (B): el “entonces…”. Conjunto de ítems en el lado derecho. Ej.: B = {plátano}.
- Soporte: qué probabilidad hay de que manzana y plátano aparezcan juntos en una transacción. Así que simplemente dividimos la frecuencia por el número de todas las transacciones.
- Confianza: probabilidad de ver B dado que aparece A. En nuestro ejemplo esto significa: ¿Qué probabilidad hay de que, si la manzana está en la cesta, entonces plátano también lo esté? Podemos calcularlo dividiendo la frecuencia de la manzana y el plátano por la frecuencia de la manzana.
- Lift: el lift indica la intensidad por el cual la probabilidad de comprar los productos consecuentes aumenta si los productos antecedentes ya han sido comprados. Así, en nuestro ejemplo, si el producto manzana está en la cesta de la compra, es 1.27 veces más probable que se compre plátano que si el producto manzana no está en la cesta.
Más información sobre la técnica ‘Market Basket Analysis’:
- https://datatab.es/tutorial/market-basket-analysis
- https://iasolver.es/todo-sobre-el-market-basket-analysis-y-su-utilidad-en-el-sector-minorista-y-retail
Desarrollo
A continuación, vamos a aplicar la lógica explicada del ‘Market Basker Analysis’ en el siguiente código de Python usando la base de datos con la que hemos hecho las consultas SQL:
import sqlite3
import pandas as pd
conexion=sqlite3.connect(r"C:\Users\alici\Desktop\Programación\Data4Business\Experiencia Junior\sanoyfresco.db")
df=pd.read_sql_query("SELECT * FROM tickets",conexion)
df.head()
conexion.close()
df.info()
df['fecha']=pd.to_datetime(df['fecha'])
df_cesta=df[['id_pedido','nombre_producto']]
df_cesta.head()
# Agrupar los productos por id_pedido e incluir en una misma celda el nombre de todos los productos del pedido
df_agrupado=df_cesta.groupby('id_pedido')['nombre_producto'].apply(lambda producto: ','.join(producto))
df_agrupado.head()
# Aplicar pd.get_dummies() para transformar los productos en columnas con 0/1
df_transacciones=df_agrupado.str.get_dummies(sep=",")
df_transacciones.head()
#**IMPORTANTE** Recordemos que vamos a calcular el soporte individual del antecedente lo cual se define como la suma de las veces que se ha comprado el producto entre el total de los pedidos. Pero al haber convertido los datos en dummies (1/0), la suma de los 1 se corresponde con la media (truco matemático). Con lo cual, pasamos directamente a calcular la media.
soporte=df_transacciones.mean()*100
soporte.sort_values(ascending=False)
# Función para calcular la confianza entre dos productos en la muestra
def confianza(antecedente, consecuente):
# Casos donde se compraron ambos productos
conjunto_ac = df_transacciones[(df_transacciones[antecedente] == 1) &
(df_transacciones[consecuente] == 1)]
# Confianza = compras conjuntas / compras de producto A
return len(conjunto_ac) / df_transacciones[antecedente].sum()
# Función para calcular el lift entre dos productos en la muestra
def lift(antecedente, consecuente):
soporte_a = df_transacciones[antecedente].mean()
soporte_c = df_transacciones[consecuente].mean()
conteo_ac = len(df_transacciones[(df_transacciones[antecedente] == 1) &
(df_transacciones[consecuente] == 1)])
soporte_ac = conteo_ac / len(df_transacciones)
return soporte_ac / (soporte_a * soporte_c)
from itertools import combinations
# Definir un umbral para la confianza mínima
umbral_confianza = 0.05
asociaciones = []
# Generar combinaciones de productos y calcular confianza y lift
for antecedente, consecuente in combinations(df_transacciones.columns, 2):
# Soporte del antecedente
soporte_a = df_transacciones[antecedente].mean()
# Calcular confianza
conf = confianza(antecedente, consecuente)
if conf > umbral_confianza:
asociaciones.append({
'antecedente': antecedente,
'consecuente': consecuente,
'soporte_a': round(soporte_a * 100,1),
'confianza': round(conf * 100,1),
'lift': round(lift(antecedente, consecuente),1)
})
# Convertir las asociaciones en un DataFrame
df_asociaciones = pd.DataFrame(asociaciones)
# Ordenar las asociaciones por confianza de mayor a menor
df_asociaciones.sort_values(by='lift', ascending=False, inplace=True)
df_asociaciones
# El bucle ha generado 399 reglas (399 combinaciones). Ahora le toca decidir al usuario cliente cuales son las reglas que nos merece la pena poner nuestros esfuerzos en base al lift: todas aquellas que contengan un lift superior a 1, a 1.5, a 2, etc...
# Generamos una tabla de los productos únicos con su 'id_producto', 'id_seccion', 'id_departamento' para enriquecer la tabla de reglas
productos_unicos=df[['id_producto','id_seccion','id_departamento','nombre_producto']].drop_duplicates()
productos_unicos.head()
# Unimos la tabla del algortimo con la tabla de los productos unicos
df_asociaciones_enriquecido=df_asociaciones.merge(productos_unicos,left_on='antecedente',right_on='nombre_producto',how='left').drop(columns=['nombre_producto'])
df_asociaciones_enriquecido.columns=['antecedente','consecuente','soporte_a','confianza','lift','id_producto_a','id_seccion_a','id_departamento_a']
df_asociaciones_enriquecido.head()
df_asociaciones_enriquecido.to_csv('reglas.csv', index=False, sep=';', decimal=',')
Conclusiones
Con estas reglas entramos en la fase del trabajo donde debemos colaborar con otros departamentos de la empresa para explotar las reglas generadas. Ejemplos:
Departamento IT: podemos pasarle estas reglas directamente al departamento de informática para que las implementen en el recomendador de la página web.
Departamento Marketing/Negocio:
- Implementar las reglas no solo en el recomendador del producto concreto, también en el checkout de compra.
- Usar el historial de compras de los clientes y meter esos productos como input en nuestra tabla de reglas, con la intención de ofrecer directamente al cliente los productos del output a través de newsletter/email personalizado.
- Se podrían desarrollar nuevos productos: cestas y packs siguiendo las reglas con los productos que se compran frecuentemente juntos. Así a lo mejor, el cliente en vez de gastarse 5 euros en el producto individual decide optar por una cesta de 15 euros donde aparezca ese producto y otros, aumentando así el Ticket Medio de Compra.
- Las reglas también permiten la generación de cupones personalizados por cliente. No tiene sentido enviar a todos los clientes los mismos cupones con las mismas ofertas cuando tenemos información sobre el historial de compra de cada cliente.
- Etc.
3. Creación de Cuadros de Mando con PowerBI
Objetivos
El dashboard se comprondrá de dos hojas: en la primera hoja se incluirán gráficos y paneles que muestren la información relevante de las ventas en el último año, la fuente única de los datos; en la segunda hoja se incluirá la aplicación de ‘Market Basket Analysis’ de nuestro algoritmo en Python.
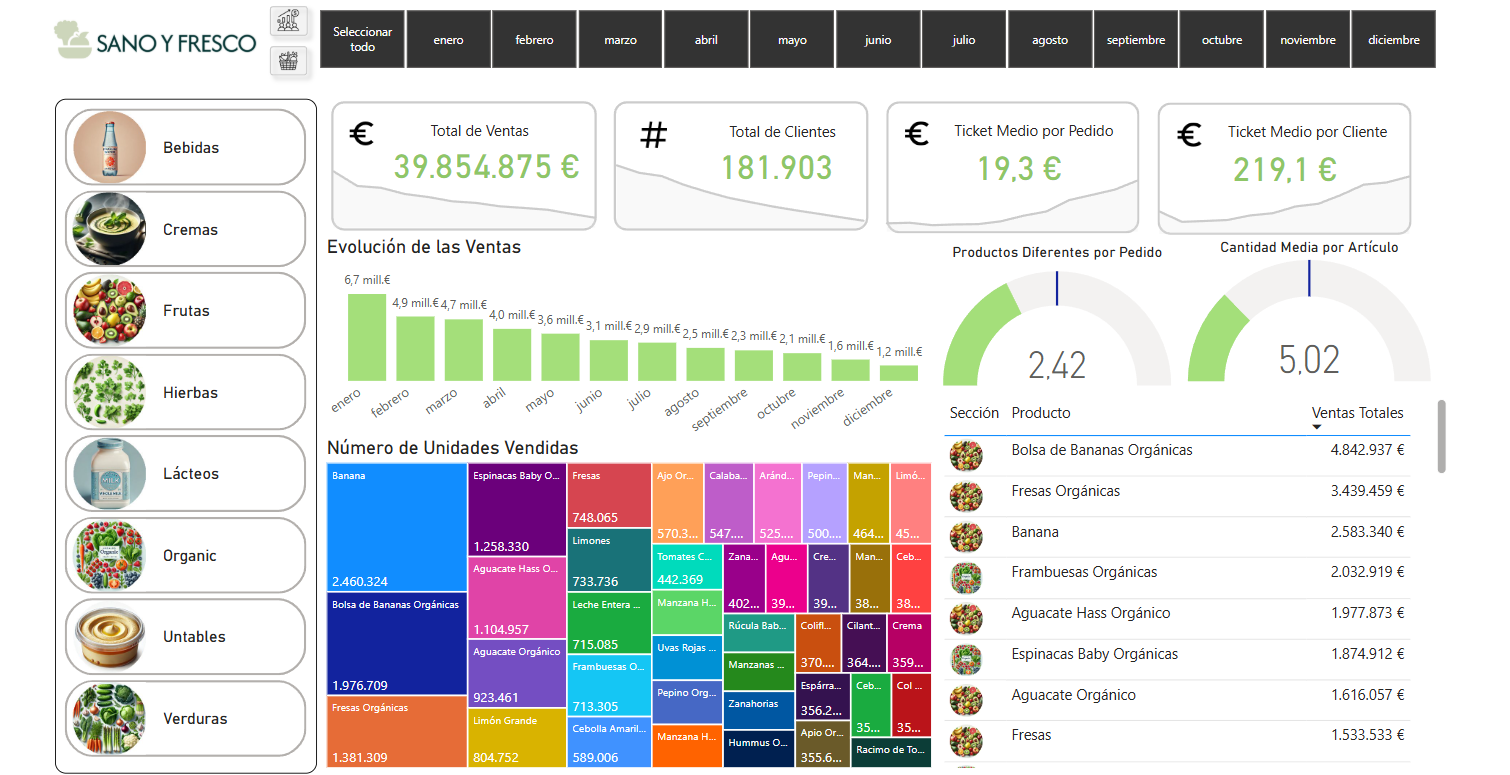
Hoja 1: Creación de la fuente única de los datos sobre las ventas para tomar acciones sobre ellos y que será común a todos los departamentos. Realizarlo en una herramienta profesional, como PowerBI.
Hoja 2:
Crear un dashboard a modo de aplicación que contenga las reglas obtenidas con nuestro algoritmo de Python, y mediante filtros poder identificar los componentes de la técnica de ‘Market Basket Analysis’ (confianza, lift, antecedente, etc.) para cada sección y productos.
Instrucciones
Hoja 1 y Hoja 2: Documento de Requerimientos Funcionales del Negocio.
Diseño Analítico
Mockup: a gusto personal siempre que contenga los contenidos exigidos en el documento de Requerimientos (se ofrece una versión en el Documento de Requerimientos).